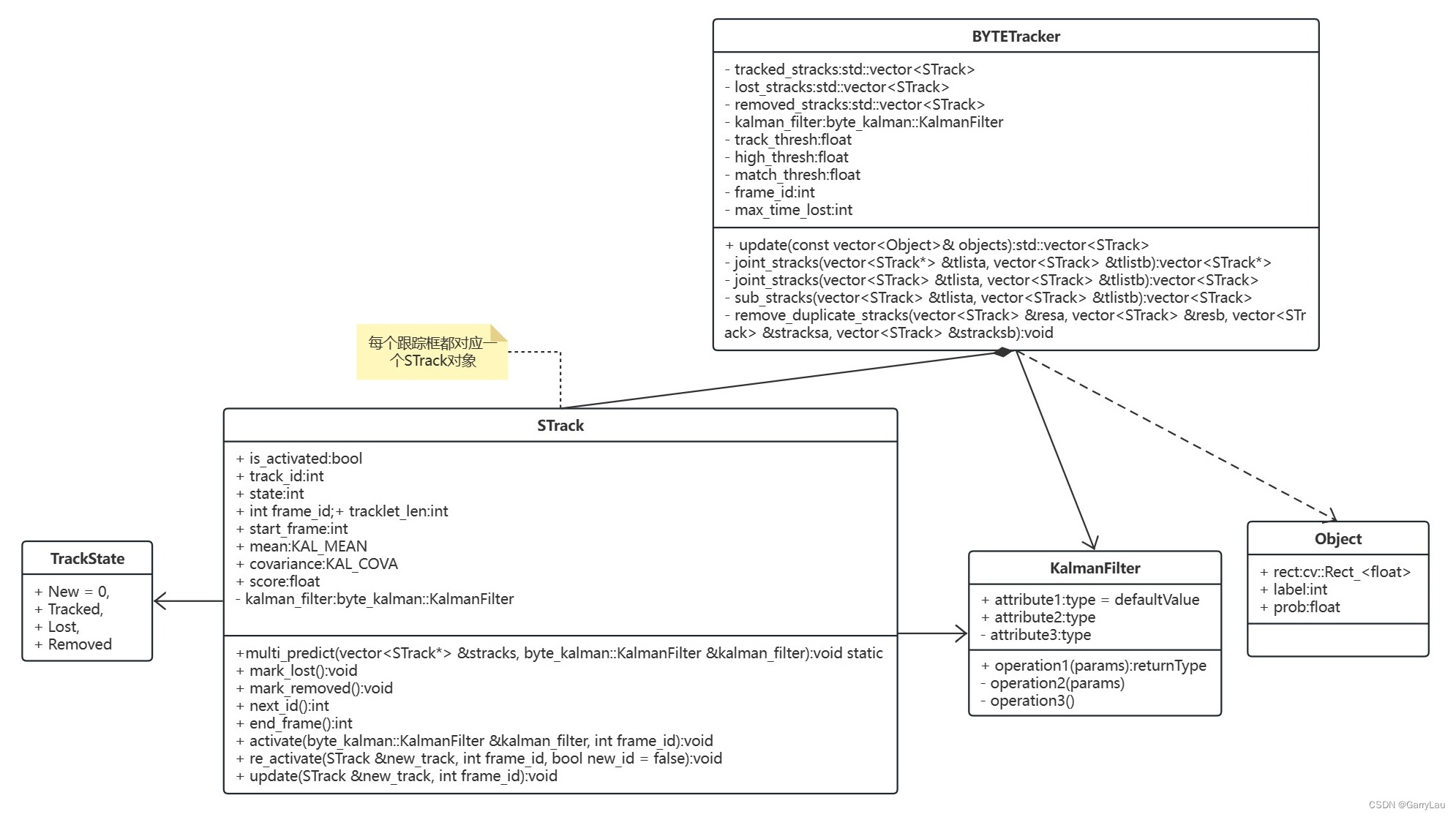
安装方式
pip install numpy 指定版本安装pip install numpy==1.14.1
官方文档:https://numpy.org/doc/stable/reference/index.html
主要介绍 Numpy 的常见基础使用,进阶使用请参考上述官方文档
Numpy 是Python 的一个科学计算基础库,提供大量科学计算相关的功能,比如数据统计,随机数生成等。提供最核心的类型是多维数组类型(ndarray),支持大量的维度数组与矩阵运算,Numpy 支持向量处理 ndarry 对象,提高程序运算速度。
1 数组的创建
numpy.array(data, ndmin, dtype):ndmin 用来指定建立几维的数组,dtype用于指定元素的类型
a = [1,2,3,4,5] # 一维 list
b = [[1,2,3,], [4,5,6]] # 二维 list
import numpy as np
one_dim_array = np.array(a)
two_dim_array = np.array(b)
print(one_dim_array)
print(two_dim_array)
a = np.array([[1,2,3]], ndmin=3) # ndmin用来指定建立几维的数组
print(a) # [[[1 2 3]]]
print(a.shape) # a.shape 用于查看 ndarray 的形状 x * x * x ...
a = np.array([1,2,3], dtype=float) # dtype用于指定元素的类型
print(a) # [1. 2. 3.]
numpy.arange(start, stop, step, dtype):类似于range()函数,创建[start, stop)左开右闭步长为 step 的数组,步长默认为 1,dtype 用于指定元素类型
a = np.arange(0, 10, 2, dtype=float)
print(a)
随机数创建,numpy.random
random中常用的方法:
| 函数 | 描述 |
|---|---|
| seed | 确定随机生成器的种子 |
| permutation | 返回一个序列的随机排列或返回一个随机排列的范围 |
| shuffle | 对一个序列就地随机排列 |
| rand | 产生均匀分布的样本值 |
| randint | 三个参数 low, high, size;[low, high),同 range函数,size 是指生成多少个数 |
| random(size) | 返回 [0.0, 1.0)范围的随机数 |
| randn(d1, d2, d3) | 返回一个或一组样本,具有正态分布(期望为 0,方差维 1) |
a = list(range(10))
print(np.random.permutation(a)) # 有返回值 不会修改 a
print(a)
np.random.shuffle(a) # 没有返回值 会修改 a
print(a)
a = np.random.rand(2, 3) # rand 中的参数可以接收任意数量的整数参数,用于确定用于生成何种形状的 ndarray 元素的值为 [0,1)
print(a.shape) # 2 * 3
a = np.random.rand(2, 3, 4)
print(a.shape) # 2 * 3 * 4
a = np.random.uniform(0, 10, (3, 2)) # np.random.uniform 也是均匀分布 可以指定生成的值范围
print(a)
a = np.random.random(size = 10)
print(a)
a = np.random.random(size = (2,3))
print(a)
a = np.random.randn(2, 3) # randn 中的参数可以接收任意数量的整数参数,用于确定用于生成何种形状的 ndarry
print(a.shape) # 2 * 3
a = np.random.randn(2, 3, 4)
print(a.shape) # 2 * 3 * 4
a = np.random.normal(loc=2, scale= 1, size = (3, 2)) # np.random.normal 也是正态分布, 可以指定正态分布的方差和期望大小
a = np.random.normal(2, 1, (3, 2))
print(a)
np.random.seed(42)
np.random.randn() # 由于种子是固定的 这里随机出来的值会是一样的 但是不加 seed 单独执行这个代码值会不一样
numpy.zeros(shape, dtype):创建全为 0 的 ndarray
numpy.ones(shape, dtype):创建全为 1 的 ndarray
numpy.empty(shape, dtype):创建未初始化元素值的 ndarray,元素值为内存中默认的值
numpy.linspace(start, stop, num=50, endpoint = True, retstep = False, dtype = None):创建一个等差数列构成的 ndarray; start 序列起始值;stop 序列结束值;num 要生成的样本数;endpoint 是否包含 stop 值;retstep 生成的数组中是否显示间距,显示间距将返回 (ndarray, step)的元组;
numpy.logspace(start, stop, num=50, endpoint = True, base = 10.0, dtype = None):创建一个等比数列构成的 ndarray; start 序列起始值,为base ** start;stop 序列结束值,为base ** stop;num 要生成的样本数;endpoint 是否包含 stop 值;base 对log的底数,默认为 10;
np.zeros((2,3), dtype=float)
np.ones((2,3), dtype=float)
np.empty((2,3), dtype=float)
a = np.arange(12).reshape(3,4) # reshape 重新调整 ndarray 维度
np.zeros_like(a) # 和a一样 shape 的 元素为 0 的 ndarray 以下以此类推
np.ones_like(a)
np.empty_like(a)
np.linspace(0, 10, num=50, endpoint = True, retstep = False, dtype = None)
np.logspace(0, 2, num=2, endpoint = True, base = 10, dtype = float)
2 ndarray 对象
ndarray:一系列同类型数据的集合,以 0 下标为开始进行集合元素的索引。
ndarray对象用于存放同类型元素的多维数组ndarray中的每个元素在内存中都有相同存储大小的区域- 组成
- 一个指向数据的指针
- 数据类型或 dtype,描述在数组中的固定大小值的格子
- 一个表示数组形状的元组,表示各维度大小的元组
2.1 常见属性
| 属性 | 说明 |
|---|---|
| ndim | 维度的数量 |
| shape | 形状,数组的维度 |
| size | 数组元素的个数, shape为(m,n)的 size 为 m * n |
| dtype | 对象的元素类型 |
| itemsize | 对象中每个元素的大小,以字节为单位 |
| flags | 内存信息 |
a = np.random.random((2,3))
print(a.ndim)
print(a.shape)
print(a.size)
print(a.dtype)
print(a.itemsize)
print(a.flags)
'''
2
(2, 3)
6
float64
8
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
'''
2.2 切片和索引
类似于 python 中 list 的切片特性
x = np.arange(10)
print(x[:2])
print(x[2:5])
# 二维
x = np.arange(0, 12).reshape(3, 4)
print([1:3, 0:2])
sub_array = np.copy(x[:2, :2])
sub_array[0][0] = 10
print(sub_array)
print(x) # x 数据不会被修改
temp = x[:2, :2]
temp[0][0] = 10
print(x) # x 数据会被修改
2.3 数组维度改变
reshape:重组原有数组
np.vstack , np.hstack 和np.concatenate:数组的拼接
np.hsplit,np.vsplit,np.split:数组的切分
np.vstack 和 np.hstack 可以用于高维数组,并且它们分别沿第一个和第二个维度进行拼接。如果需要沿其他维度拼接,可以使用 np.concatenate 函数,并指定 axis 参数。
np.split 可以沿任何轴切分数组。你需要提供要切分的位置和轴参数。np.hsplit 用于沿水平轴(第 1 轴)切分数组,主要用于二维及以上维度的数组。np.vsplit 用于沿垂直轴(第 0 轴)切分数组,主要用于二维及以上维度的数组。
x = np.arange(0, 12)
print(x.shape)
x = x.reshape(3, 4)
print(x.shape)
a = np.array([[1,2], [3,4]]) # 2, 2
b = np.array([[5,6]]) # 1, 2
print(np.vstack((a, b))) # 垂直拼接
print(np.hstack((a, b.T))) # 水平拼接
# 三维 数组拼接
# 创建三个 3 维数组 (2, 2, 3)
arr1 = np.array([[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]])
arr2 = np.array([[[13, 14, 15], [16, 17, 18]],
[[19, 20, 21], [22, 23, 24]]])
arr3 = np.array([[[25, 26, 27], [28, 29, 30]],
[[31, 32, 33], [34, 35, 36]]])
# 沿着轴0拼接
concat_axis0 = np.concatenate((arr1, arr2, arr3), axis=0)
print("\n沿轴0拼接结果:\n", concat_axis0) # (6, 2, 3)
# 沿着轴1拼接
concat_axis1 = np.concatenate((arr1, arr2, arr3), axis=1)
print("\n沿轴1拼接结果:\n", concat_axis1) # (2, 6, 3)
# 沿着轴2拼接
concat_axis2 = np.concatenate((arr1, arr2, arr3), axis=2)
print("\n沿轴2拼接结果:\n", concat_axis2) # (2, 2, 9)
2.4 转置操作
二维数组的转置 就是 矩阵的转置运算
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("原数组:\n", arr)
transposed_arr = arr.T
print("转置后的数组:\n", transposed_arr)
# 创建一个三维数组
arr = np.arange(24).reshape(2, 3, 4)
print("原数组:\n", arr)
# 默认转置,交换所有维度
transposed_arr = arr.transpose()
print("\n默认转置 (交换所有维度):\n", transposed_arr)
# 指定轴顺序进行转置 (这里我们交换第一个和第二个轴)
transposed_arr_012 = arr.transpose(1, 0, 2)
print("\n指定轴顺序 (1, 0, 2) 的转置:\n", transposed_arr_012)
# 使用 ndarray.T 进行转置 (默认交换所有维度)
transposed_arr_T = arr.T
print("\n使用 ndarray.T 进行转置:\n", transposed_arr_T)
2.5 算术运算
算术运算需要保证 操作的两个 ndarray 维度需要尽量保持一致;但是当维度不一致的时候,可能也可以进行运算,因为numpy存在广播机制
广播机制:
- 如果数组的维度数不相同,则在较小的数组的形状前面加上 1,直到所有数组具有相同的维度数。
- 两个数组在某个维度上的长度是相同的,或者其中一个数组在该维度上的长度是 1。
- 如果以上条件都不满足,则引发异常。
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
print("加法:", arr1 + arr2)
print("减法:", arr1 - arr2)
print("乘法:", arr1 * arr2)
print("除法:", arr1 / arr2)
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 标量与数组的加法运算
result = arr + 1
print("标量与数组的加法运算:\n", result)
# 创建一个二维数组
arr2d = np.array([[1, 2, 3], [4, 5, 6]])
# 创建一个一维数组
arr1d = np.array([10, 20, 30])
# 一维数组与二维数组的加法运算
result = arr2d + arr1d
print("一维数组与二维数组的加法运算:\n", result)
# 创建两个形状不同的二维数组
arr2d_1 = np.array([[1, 2, 3], [4, 5, 6]])
arr2d_2 = np.array([[10], [20]])
# 不同形状的二维数组加法运算
result = arr2d_1 + arr2d_2
print("不同形状的二维数组加法运算:\n", result)
以下不符合广播规则,因为 数组在第一个维度上的长度分别为 4 和 3,没有一个长度为 1,因此它们无法广播成相同的形状。
arr1 = np.array([1, 2, 3, 6])
arr2 = np.array([4, 5, 6])
print("加法:", arr1 + arr2)
2.6 向上向下取整与聚合操作
单维度 数组的操作
arr = np.array([1.2, 2.5, 3.7, 4.4])
print("向下取整:", np.floor(arr))
print("向上取整:", np.ceil(arr))
arr = np.array([1, 2, 3, 4, 5])
print("数组之和:", np.sum(arr))
print("数组的平均值:", np.mean(arr))
print("数组的标准差:", np.std(arr))
print("数组的最大值:", np.max(arr))
print("数组的最小值:", np.min(arr))
二维及以上维度的数组 操作
# 创建一个二维数组
arr2d = np.array([[1, 2, 3], [4, 5, 6]])
# 求和
sum_all = np.sum(arr2d)
sum_axis0 = np.sum(arr2d, axis=0) # [5 7 9]
sum_axis1 = np.sum(arr2d, axis=1) # [ 6 15]
# 平均值
mean_all = np.mean(arr2d)
mean_axis0 = np.mean(arr2d, axis=0) # [2.5 3.5 4.5]
mean_axis1 = np.mean(arr2d, axis=1) # 2. 5.]
# 最大值
max_all = np.max(arr2d)
max_axis0 = np.max(arr2d, axis=0) # [4 5 6]
max_axis1 = np.max(arr2d, axis=1) # [3 6]
# 最小值
min_all = np.min(arr2d)
min_axis0 = np.min(arr2d, axis=0) # [1 2 3]
min_axis1 = np.min(arr2d, axis=1) # [1 4]
# 创建一个三维数组
arr3d = np.arange(24).reshape(2, 3, 4)
# 求和
sum_all = np.sum(arr3d)
sum_axis0 = np.sum(arr3d, axis=0)
'''
[[12 14 16 18]
[20 22 24 26]
[28 30 32 34]]
'''
sum_axis1 = np.sum(arr3d, axis=1)
'''
[[12 15 18 21]
[48 51 54 57]]
'''
sum_axis2 = np.sum(arr3d, axis=2)
'''
[[ 6 22 38]
[54 70 86]]
'''